/**
* @Description:Java内存模型-有序性
* @Author:chenxi
* @Date:2020/3/22
**/
public class JMMOrderTest {
private static int a, b = 0;
private static int x, y = 0;
public static void main(String[] args) throws InterruptedException {
int count = 0;
for (; ; ) {
count++;a = 0;b = 0;
Thread thread_1 = new Thread(new Runnable() {
@Override
public void run() {
//阻塞
int block = 0;
do{
block++;
}while (block < 20000);
a = 1;
x = b;
}
});
Thread thread_2 = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
y = a;
}
});
thread_1.start();
thread_2.start();
thread_1.join();
thread_2.join();
if (x == 0 && y == 0) {
System.err.println("execute count = " + count + " a-b-x-y: " + a + "-" + b + "-" + x + "-" + y);
System.err.println("x and y is 0");
break;
} else {
System.out.println("execute count = " + count + " a-b-x-y: " + a + "-" + b + "-" + x + "-" + y);
}
}
}
}
假设会出现以下场景:
假设Thread_1先启动执行结束、Thread_2后启动执行、Thread_2后启动执行
结果为:a = 1;b = 1;x = 0;y = 1;
假设Thread_2先启动执行结束、Thread_1后执行
结果为:a = 1;b = 1;x = 1;y = 0;
假设Thread_1先启动执行,在代码块中a = 1执行过程中阻塞了,Thread_2执行时在Thread_1执行x = b之前先执行b = 1,那么x,y = 1
执行顺序如下
Thread_1:
a = 1;
Thread_2:
b = 1;
Thread_1:
x = b; // x = b = 1;
Thread_2:
y = a; // y = a = 1;
控制台输出如下:
......
execute count = 1689 a-b-x-y: 1-1-0-1
execute count = 1690 a-b-x-y: 1-1-1-0
execute count = 1690 a-b-x-y: 1-1-1-1
execute count = 1690 a-b-x-y: 1-1-0-0
x and y is 0
那么为什么会出现 1-1-0-0 ???
CPU会进行指令重排:
在执行程序时,为了提高性能,编译器和处理器通常会对指令做重排序
Thread thread_1 = new Thread(new Runnable() {
@Override
public void run() {
//阻塞
int block = 0;
do{
block++;
}while (block < 20000);
x = b; //改变执行顺序a = 1; //改变执行顺序
}
});
Thread thread_2 = new Thread(new Runnable() {
@Override
public void run() {
y = a; //改变执行顺序 b = 1; //改变执行顺序
}
});
假设Thread_1先启动执行,在代码块中x = b执行过程中阻塞了,Thread_2执行时在Thread_1执行a = 1之前先执行y = a,那么x,y = 0
执行顺序如下
Thread_1:
x = b; // x = b = 0;
Thread_2:
y = a; // y = a = 0;
Thread_1:
a = 1;
Thread_2:
b = 1;
此时,我们使用volatile来修饰x,y变量:
private static volatile int x, y = 0;
执行程序,x,y = 0的结果将不会再出现
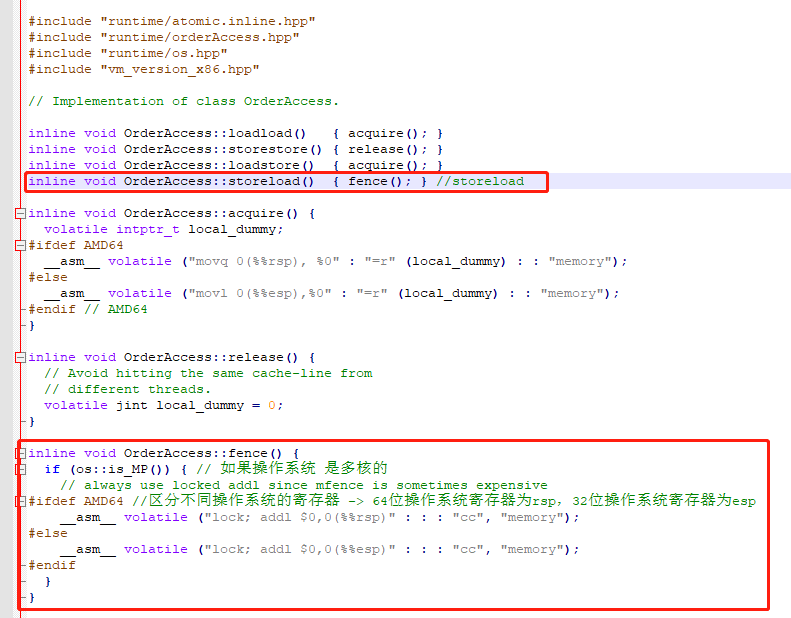
因为volatile在写后面加上了storeload(内存屏障)
volatile如何防止指令重排:
volatile关键字通过”内存屏障“来防止指令被重排序
JMM采取保守策略,基于保守策略JMM内存屏障插入策略:
在每个volatile写操作的前面插入一个StoreStore屏障
在每个volatile写操作的后面插入一个StoreLoad屏障
在每个volatile读操作的后面插入一个LoadLoad屏障
在每个volatile读操作的后面插入一个LoadStore屏障
代码分析:
Thread thread_1 = new Thread(new Runnable() {
@Override
public void run() {
//阻塞
......//此处代码省略
a = 1; //volatile写后增加storeLoad(内存屏障)
x = b; //先volatile读,再普通写
}
});
Thread thread_2 = new Thread(new Runnable() {
@Override
public void run() {
b = 1; //volatile写后增加storeLoad(内存屏障)
y = a; //先volatile读,再普通写
}
});
自定义内存屏障:
private static int x, y = 0;
......//此处代码省略
Thread thread_1 = new Thread(new Runnable() {
@Override
public void run() {
//阻塞
......//此处代码省略
a = 1;
//手动增加内存屏障
getUnsafe().storeFence();
x = b;
}
});
Thread thread_2 = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
//手动增加内存屏障
getUnsafe().storeFence();
y = a;
}
});
private static Unsafe getUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
}catch (Exception e){
e.printStackTrace();
}
return null;
}



 ||
||  ||
||


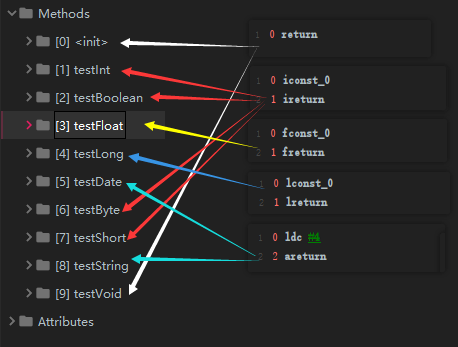
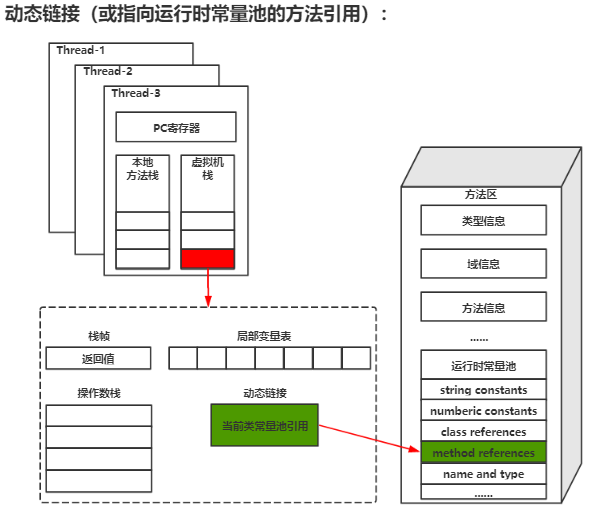
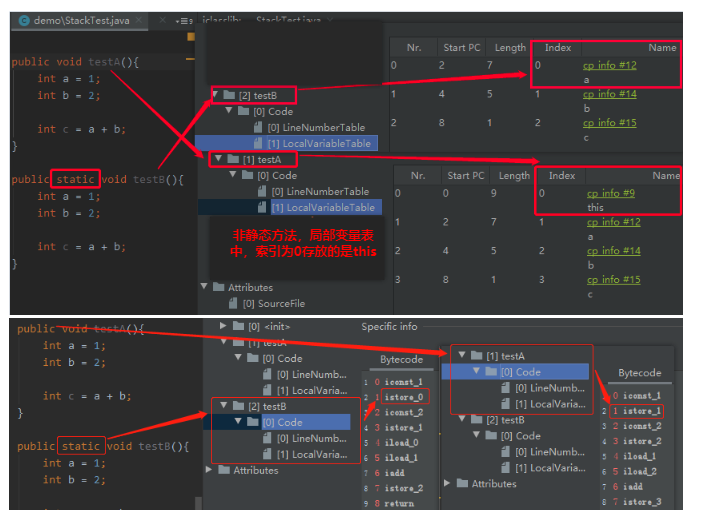
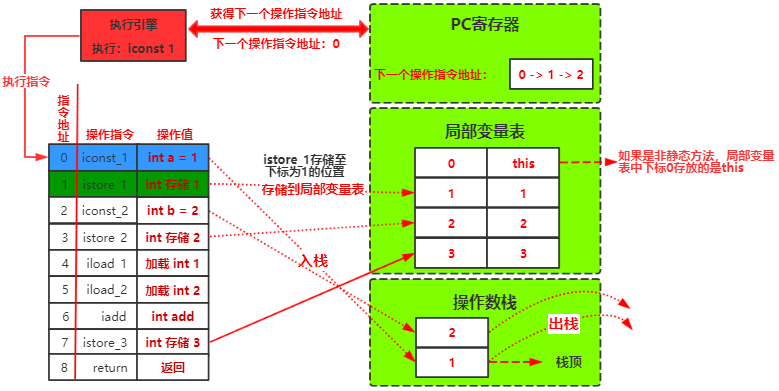
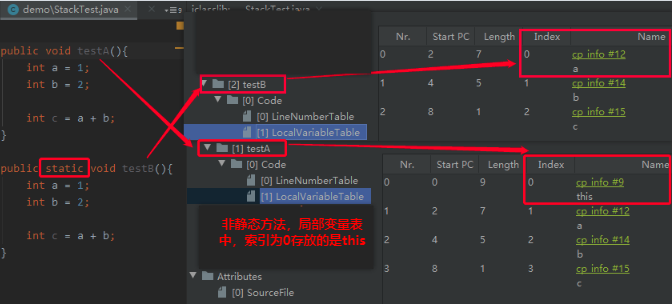 Slot的重复利用:
Slot的重复利用: