错误信息:
解决办法:
文件夹赋予用户权限
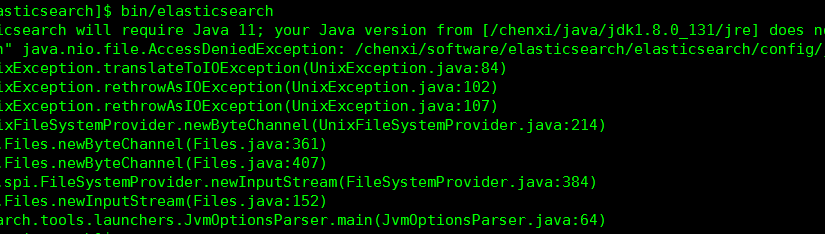
[root@chenxi elasticsearch]# chown -R eschenxi:esgroup /chenxi/software/elasticsearch #”/chenxi/software/elasticsearch” 为安装目录
错误信息:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
ERROR: [1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
ERROR: Elasticsearch did not exit normally – check the logs at /chenxi/software/elasticsearch/logs/elasticsearch.log
解决办法:
[root@chenxi elasticsearch]# vim /etc/sysctl.conf
在文件末尾追加:vm.max_map_count=655360
保存后执行
[root@chenxi elasticsearch]# sysctl -p
错误信息: [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
ERROR: [5] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
[4]: failed to install; check the logs and fix your configuration or disable system call filters at your own risk
[5]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:
[root@chenxi elasticsearch]# vim /etc/security/limits.conf
## 65535修改为65536
* soft nofile 65536
* hard nofile 65536
## 文件末尾追加
* soft nproc 4096
* hard nproc 4096
修改文件后保存并“关闭会话,重新登陆服务器”
错误信息:system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
ERROR: [2] bootstrap checks failed
[1]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
[2]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:
##在elasticsearch.yml修改并添加配置项
[root@chenxi elasticsearch]# vim config/elasticsearch.yml
# ———————————– Memory ———————————–
#
# Lock the memory on startup:
# 取消注释并设置值为false
bootstrap.memory_lock: false
# 追加配置项
bootstrap.system_call_filter: false
错误信息: the default discovery settings are unsuitable for production use; at least one of
ERROR: [1] bootstrap checks failed
[1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:
##在elasticsearch.yml添加配置项
[root@chenxi elasticsearch]# vim config/elasticsearch.yml
# ——————————— Discovery ———————————-
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is [“127.0.0.1”, “[::1]”]
#
#discovery.seed_hosts: [“host1”, “host2”]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
# 取消注释,并保留一个节点
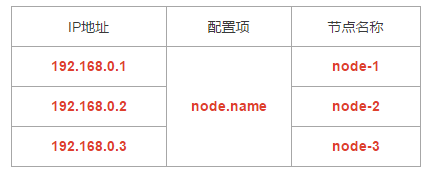
cluster.initial_master_nodes: [“node-1”]
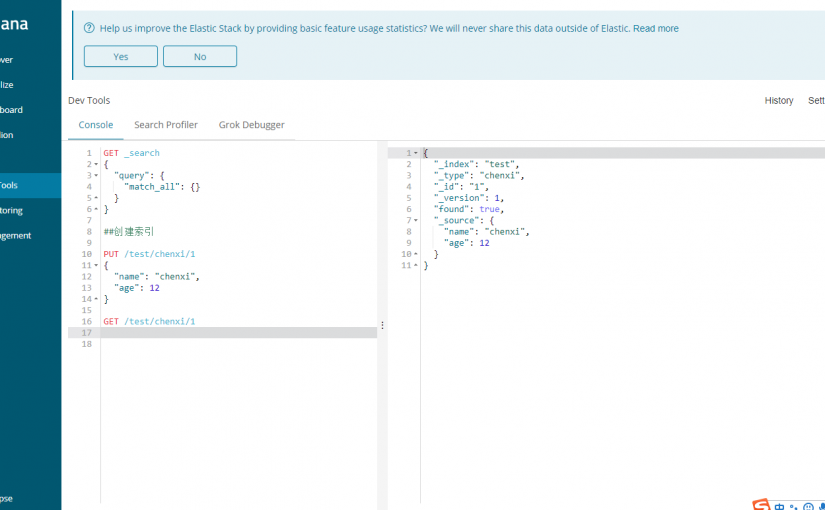
测试Es启动是否正常:
http://IP:9092
{
“name” : “chenxi”,
“cluster_name” : “elasticsearch”,
“cluster_uuid” : “_na_”,
“version” : {
“number” : “7.6.0”,
“build_flavor” : “default”,
“build_type” : “tar”,
“build_hash” : “7f634e9f44834fbc12724506cc1da681b0c3b1e3”,
“build_date” : “2020-02-06T00:09:00.449973Z”,
“build_snapshot” : false, “lucene_version” : “8.4.0”, “minimum_wire_compatibility_version” : “6.8.0”, “minimum_index_compatibility_version” : “6.0.0-beta1”
},
“tagline” : “You Know, for Search”
}