Exactly Once语义:
将服务器的ACK级别设置为-1,可以保证Producer到Server之间不会丢失数据,即At Least Once 语义。相对的,将服务器ACK级别设置为0,可以保证生产者每条消息只会被发送一次,即At Most Once语义。
At Least Once可以保证数据不丢失,但是不能保证数据不重复;相对的, At Least Once可以保证数据不重复,但是不能保证数据不丢失。
对于一些非常重要的信息,比如交易数据,下游数据消费者要求数据既不重复也不丢失,在 0.11 版本以前的 Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。对于多个下游应用的情况,每个都需要单独做全局去重,这就对性能造成了很大影响。
0.11 版本的 Kafka,引入了一项重大特性:幂等性。幂等性就是指Producer不论向Broker发送多少次重复数据,Broker都只会持久化一条。幂等性结合At Least Once语义,就构成了Kafka的Exactly Once语义。
At Least Once + 幂等性 = Exactly Once
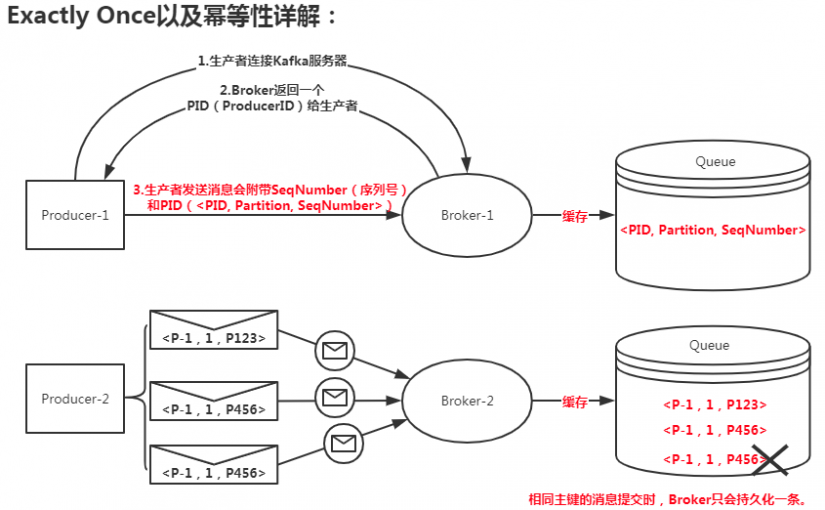 要启用幂等性,只需要将Producer的参数中enable.idompotence设置为true(设置为true时,ACK默认设置为-1)。
Kafka的幂等性实现是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
PID重启就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
要启用幂等性,只需要将Producer的参数中enable.idompotence设置为true(设置为true时,ACK默认设置为-1)。
Kafka的幂等性实现是将原来下游需要做的去重放在了数据上游。开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。而Broker端会对<PID, Partition, SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会持久化一条。
PID重启就会变化,同时不同的Partition也具有不同主键,所以幂等性无法保证跨分区跨会话的Exactly Once。
Kafka消费者:
consumer 采用 pull(拉) 模式从 broker 中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回
分区分配策略 :
一个consumer group中有多个consumer,一个topic有多个partition,所以会涉及到partition的分配问题,如何确定哪个partition由哪个consumer来消费?
Kafka有两种分配策略:RoundRobin(轮循)和 Range(范围)。
Kafka默认使用的是Range分配策略。
可设置partition.assignment.strategy的值进行自由调整(RoundRobin、Range)。

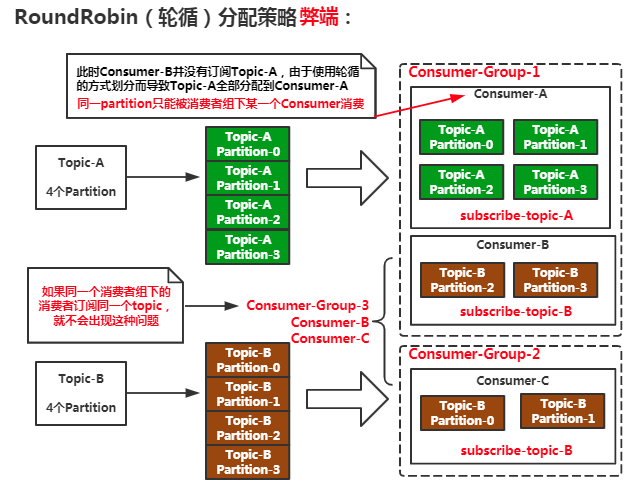
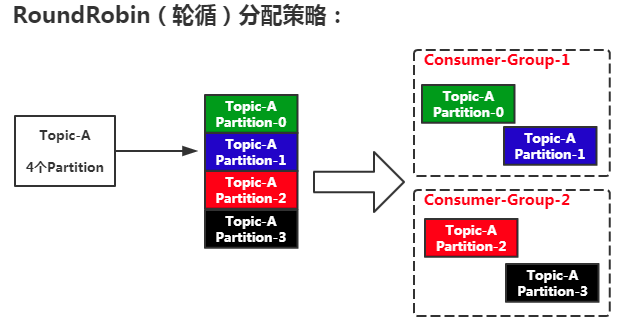 RoundRobin(轮循):根据消费者组来进行轮循划分,把消费者组看成一个整体来进行轮循。(需要保证同一个消费者组下的消费者订阅同一个topic)
RoundRobin(轮循):根据消费者组来进行轮循划分,把消费者组看成一个整体来进行轮循。(需要保证同一个消费者组下的消费者订阅同一个topic)
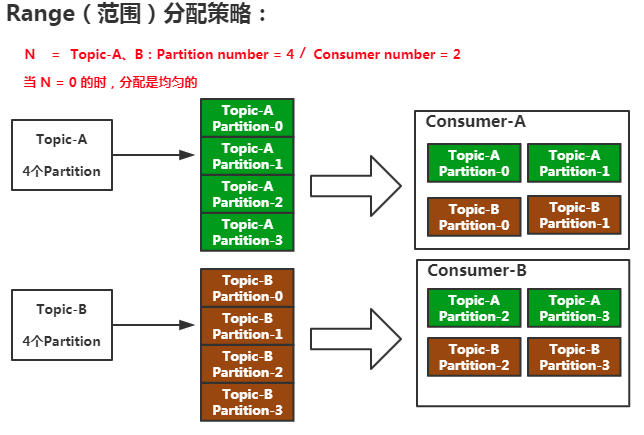 Range(范围):根据(分区数量 / 消费者组数量 = 范围)划分。
假设有2个消费者(cA,cB)和2个topic分别有3个partition
(topic-A{a-p-0,a-p-1,a-p-2}), topic-B{b-p-0,b-p-1,b-p-2})
分配后的结果是:
M = 3/2
cA = a-p-0,a-p-1,b-p-0,b-p-1
cB = a-p-2,b-p-2
Range(范围):根据(分区数量 / 消费者组数量 = 范围)划分。
假设有2个消费者(cA,cB)和2个topic分别有3个partition
(topic-A{a-p-0,a-p-1,a-p-2}), topic-B{b-p-0,b-p-1,b-p-2})
分配后的结果是:
M = 3/2
cA = a-p-0,a-p-1,b-p-0,b-p-1
cB = a-p-2,b-p-2
 导致前M个分配不均匀,消费者负载。
导致前M个分配不均匀,消费者负载。
