集群三台机器
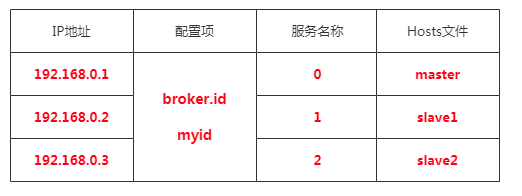
在Hosts文件中建立域名和IP的映射配置(方便解析): vim /etc/hosts
192.168.0.1 master
192.168.0.2 slave1
192.168.0.3 slave2
配置环境变量:vim /etc/profile
注意修改安装目录
#kafka eagle config
export KE_HOME=/opt/module/eagle
export PATH=$PATH:$KE_HOME/bin
使环境变量生效:source /etc/profile
主要配置修改:
###################################### # multi zookeeper & kafka cluster list ###################################### kafka.eagle.zk.cluster.alias=master,slave1,slave2 master.zk.list=master:2181,slave1:2181,slave2:2181 slave1.zk.list=master:2181,slave1:2181,slave2:2181 slave2.zk.list=master:2181,slave1:2181,slave2:2181 ###################################### # broker size online list ###################################### cluster1.kafka.eagle.broker.size=20 ###################################### # zk client thread limit ###################################### kafka.zk.limit.size=25 ###################################### # kafka eagle webui port ###################################### kafka.eagle.webui.port=8048 ###################################### # kafka offset storage ###################################### master.kafka.eagle.offset.storage=kafka slave1.kafka.eagle.offset.storage=kafka slave2.kafka.eagle.offset.storage=kafka ###################################### # kafka metrics, 30 days by default ###################################### kafka.eagle.metrics.charts=true kafka.eagle.metrics.retain=30 ###################################### # kafka sql topic records max ###################################### kafka.eagle.sql.topic.records.max=5000 kafka.eagle.sql.fix.error=false ###################################### # delete kafka topic token ###################################### kafka.eagle.topic.token=keadmin ###################################### # kafka sasl authenticate ###################################### master.kafka.eagle.sasl.enable=false master.kafka.eagle.sasl.protocol=SASL_PLAINTEXT master.kafka.eagle.sasl.mechanism=SCRAM-SHA-256 master.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.scram.ScramLoginModule required username="kafka" password="kafka-eagle"; master.kafka.eagle.sasl.client.id= master.kafka.eagle.sasl.cgroup.enable=false master.kafka.eagle.sasl.cgroup.topics= slave1.kafka.eagle.sasl.enable=false slave1.kafka.eagle.sasl.protocol=SASL_PLAINTEXT slave1.kafka.eagle.sasl.mechanism=PLAIN slave1.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="kafka-eagle"; slave1.kafka.eagle.sasl.client.id= slave1.kafka.eagle.sasl.cgroup.enable=false slave1.kafka.eagle.sasl.cgroup.topics= slave2.kafka.eagle.sasl.enable=false slave2.kafka.eagle.sasl.protocol=SASL_PLAINTEXT slave2.kafka.eagle.sasl.mechanism=PLAIN slave2.kafka.eagle.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="kafka" password="kafka-eagle"; slave2.kafka.eagle.sasl.client.id= slave2.kafka.eagle.sasl.cgroup.enable=false slave2.kafka.eagle.sasl.cgroup.topics= ###################################### # kafka sqlite jdbc driver address ###################################### #kafka.eagle.driver=org.sqlite.JDBC #如需使用eagle自带数据库,则修改安装路径 #kafka.eagle.url=jdbc:sqlite:/opt/module/eagle/db/ke.db #kafka.eagle.username=root #kafka.eagle.password=www.kafka-eagle.org ###################################### # kafka mysql jdbc driver address ###################################### kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://slave2:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull kafka.eagle.username=root kafka.eagle.password=123a123@
##授权启动文件:chomd 777 ke.sh
##启动:ke.sh start
eagle常用命令:start|stop|restart|status|stats|find|gc|jdk|version
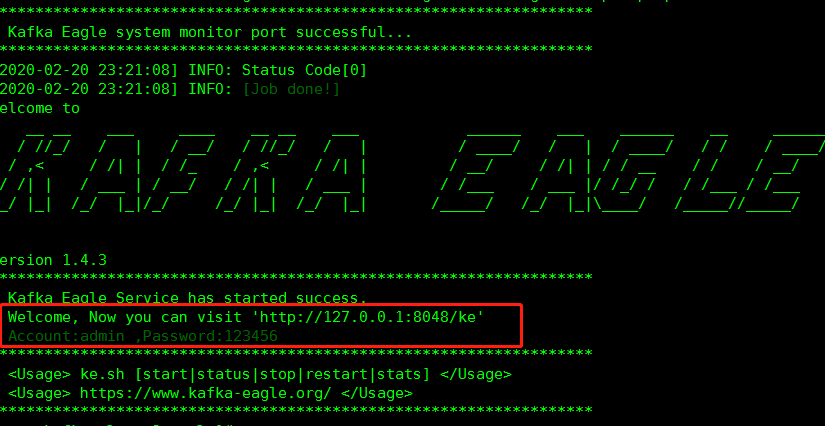
访问:ip:8048/ke admin/123456
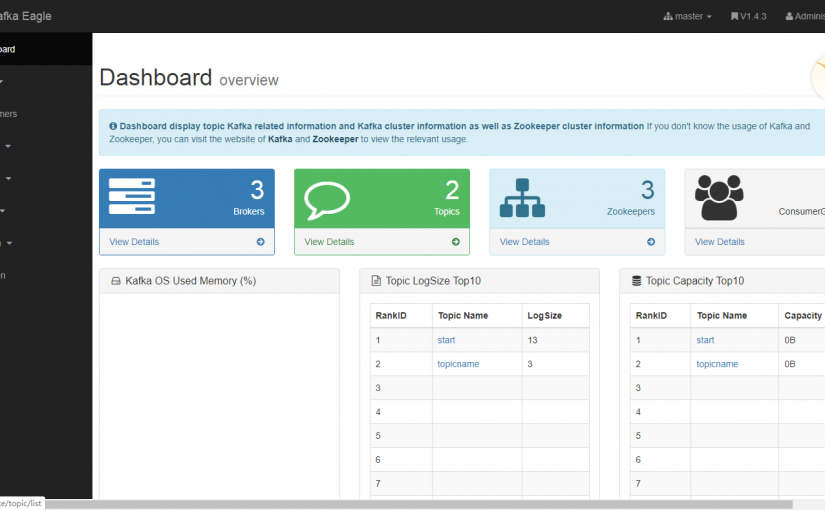
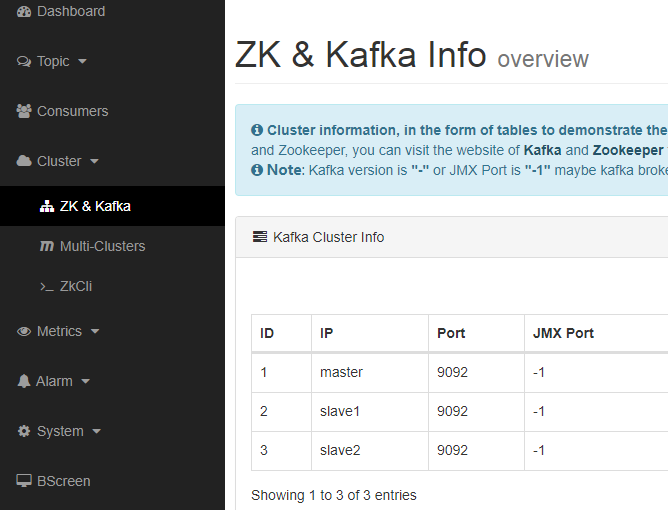

 [
[


 slave1被选举称为leader,master和slave2被选为follower。
三台分别显示leader或follower则搭建成功。
zookeeper搭建常见问题:
slave1被选举称为leader,master和slave2被选为follower。
三台分别显示leader或follower则搭建成功。
zookeeper搭建常见问题: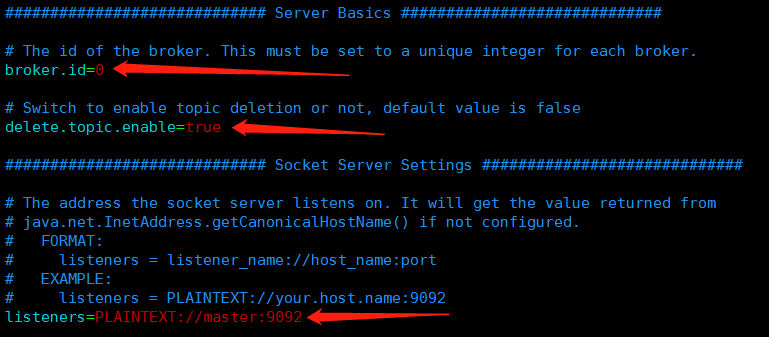
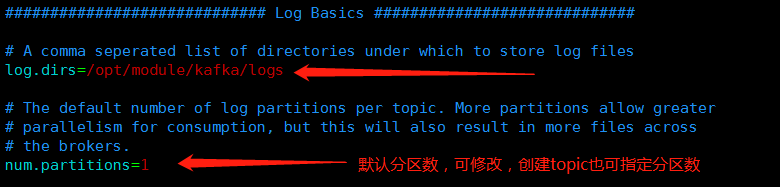
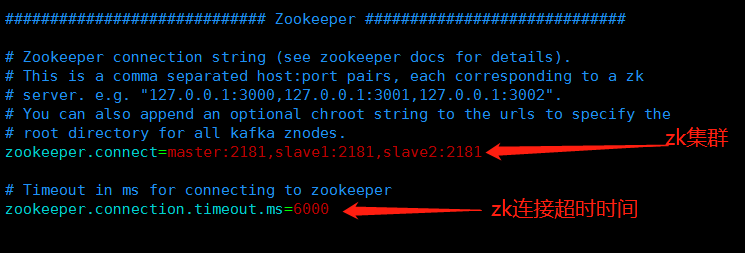 ###启动Kafka
[root@kafka-master
###启动Kafka
[root@kafka-master 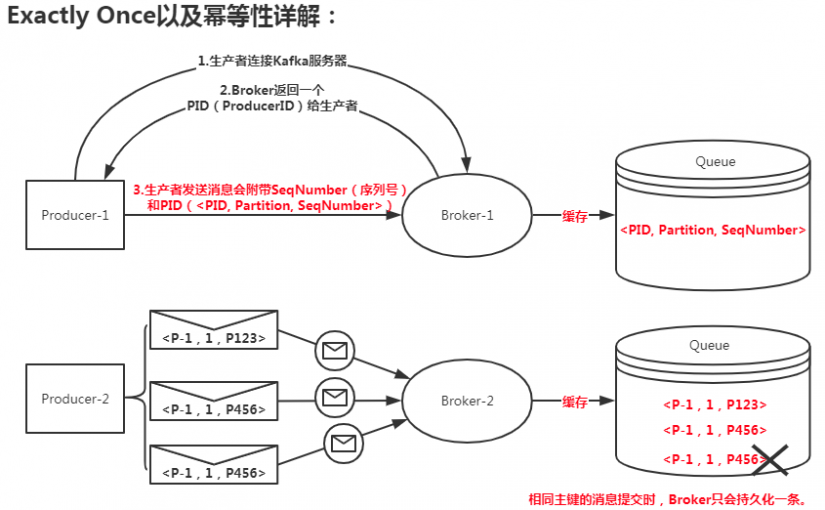

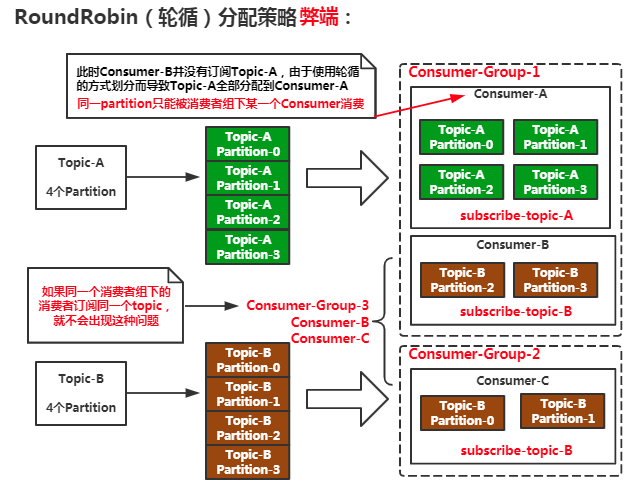
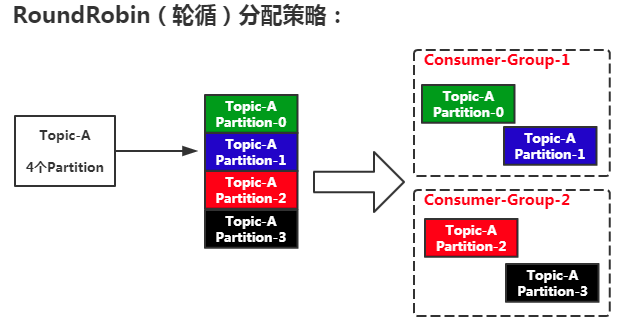 RoundRobin(轮循):
RoundRobin(轮循):